














LooperGP
A loopable sequence model for live coding performance using GuitarPro tablature
GitHub Links: LooperGP, LooperMIDI
My Masters's thesis at QMUL focused on addressing barriers that prevent generative deep learning models from being adopted as a live music performance tool. I specifically focused on the potential use of symbolic generation in live coding, an artform of performing electronic music by programming in a scripting language (common ones include SuperCollider, Tidal Cyles and Sonic Pi). Despite their impressive offline results, deep learning models for symbolic music generation are not widely used in live performances due to a deficit of musically meaningful control parameters and a lack of structured musical form in their outputs. To address these issues we introduce LooperGP, a method for steering a Transformer-XL model towards generating loopable musical phrases of a specified number of bars and time signature, enabling a tool for live coding performances. More details and audio examples can be found in the video below:
This work was published and presented at EvoMUSART 2023, receiving the Oustanding Student award. The preprint is available on arXiv, and the full set of audio examples used in the listening test are on Google Drive. After publication, I implemented an improved version of the loop extraction algorithm that works with MIDI data and addresses some of the repetition issues in the original paper. This updated implementation is posted in the GitHub links above.
Creating With The Machine
Series of interactive algorithmic compositions for human and machine musicians
GitHub Links: machine-cycle, rnn-on-bach, breathe
"Creating with the Machine" is a set of compositions that combine algorithmic and traditional methods of music composition into live performances to explore how interactive generative algorithms can influence creativity in musical improvisation, and create a compelling listening experience for the audience. In each composition, data streams from a musician's performance are sent as input parameters to an algorithm, influencing the music that is generated. As the algorithm is influenced by the performer, the performer is also musically influenced by the output of the algorithm in a real time closed loop. This project was awarded the Henry Armero Memorial Award, an award to honor the memory of Henry Armero, at the Meeting of the Minds research symposium. Sara also presented Creating with the Machine as a talk on algorithmic composition techniques at the 2019 Hackaday Superconference in Los Angeles. A recording of Sara's Supercon talk is included below.
Three compositions were created and premiered, each showcasing a different algorithmic composition technique. The first composition, "Machine Cycle," utilizes Markov chains to melodically alter and playback phrases from a keyboard player in real time. As a pianist improvises on a MIDI keyboard, the algorithm randomly saves phrases they play. When a new phrase is added, a Markov chain of potential embellishments (such as passing tones, neighbor tones, rhythmic alterations and skipped notes) is created and saved to a bank. Throughout the piece the algorithm generates its own phrases from its bank of Markov chains and plays them back to the performer. The “conductor” of the piece controls the probability of each embellishment occurring and how often phrases are played using a MIDI controller. Machine Cycle has a score that contains the structural outline of the piece without dictating specific notes. The conductor is also responsible for interpretting the score and leading the musicians through the sections of the piece.
The second composition, "Recurrent Neural Networks on Bach," generates polyphonic phrases during the training of an LSTM neural network to accent a gradual transition from chaotic noise to tonal harmony. A 3 layer LSTM was trained on over 400 Bach chorales using Google Magenta, and a checkpoint of the model weights was saved every half hour during training. During performance, a Python script maintains a queue of MIDI files containing 4 voice 8 bar phrases that are generated from the ascending checkpoints. MIDI note messages are sent from Python to a virtual instrument in Logic Pro X. Using a MIDI controller, the performer controls progress through the checkpoints, tempo, and other effects to shape the structure of the piece. The piece starts with random weights, and moves through the checkpoints to weights of the fully trained network.
The third composition, "Breathe," captures the breathing of a performing guitarist as they improvise to manipulate the frequency spectrum of their instrument and control granular synthesis. As the guitarist improvises they are able to record phrases with a foot pedal that run through a granular synthesizer. They can also use the foot pedal to capture an FFT snapshot of their current audio, freeze it, and play it back as a drone. Up to six drones can play, and they each continuously ramp to new amplitudes on a designated beat. Meanwhile, the breath of the performer is picked up by a lapel mic sitting under their noise. The amplitude of their breath signal influences the grain size and rate of the granular synthesizer, and the rate at which each drone ramps to a new amplitude, creating a piece that ebbs and flows with the performer's breath.
Eye Motion Loop Instrument
Max MSP interface for hands-free music making with Eye Gaze technology
Details Coming Soon
Digital Subharmonicon
Digital replica of the Moog subharmonicon, implemented on the Bela hardware platform
GitHub Link: digital-subharmonicon
This is a digital implementation of the polyrhymic Moog Subharmonicon synthesizer with a mix of hardware and software controls. The synthesizer features two voltage controlled oscillators with controllable subharmonics that share a resonant low pass filter. Two step sequencers control the frequency of the oscillators, and the four rhythm generators allow the creation of polyrhythms by generating integer divisions of the main sequencer tempo. Aliasing effects in the digital system are reduced using the differentiated parabolic waveform method, though not eliminated completely. Despite these artifacts, the digital subharmonicon is potential to be a low cost, open source alternative to the expensive Moog original.
Let's Go
Algorithmic step sequencer and melody generator based on a live game of Go
GitHub Link: lets-go
Let's Go uses computer vision to track the positions of the black and white tokens in the popular board game Go. By representing a board state as a matrix, we can transform the Go board into a step sequencer and melody creator, allowing the two players to create music together that builds as the game progresses.



OpenCV was used to process a live video stream of the Go board captured with an HD webcam. The algorithm converts the picture to black and white to isolate the white go pieces, then inverts the frame to isolate the black.

We then use OpenCV's blob detection algorithm to find the center of each game piece on the board. Assuming the game board does not move, we can interpolate the location of each intersection on the board given the location of the four edges of the board. From here, we can determine the closest intersection to each game piece and generate two 13x13 binary matrices representing the current game state. These matrices are sent to Max MSP using Open Sound Control (OSC).
Within the Max patch, the matrix of black pieces was used to control a step sequencer of percussion sounds. The matrix of white pieces was split in half, where the left half controlled 7 drone sounds and the right half controlled 6 melody lines.
The samples used for this project were created by Abby Adams and Julian Koreniowsky in Logic Pro X. The percussive sounds came from numerous drum patches designed by Logic ranging from kick drums to frog noises. The melodic pieces was based off of A Major suspended drone(ADEFA#C#E), synth bass noises and LFO sound effects. Melody lines play on a fixed loop starting on the next beat after the corresponding game piece was put down. The percussion sounds were based on a 3+3+2+2+3 rhythm, representing the 13 spaces of the game board.
Singing Synthesizer
Pipeline for synthesizing lyrics, melody and vocalization using machine learning
GitHub Links: melody-generation, lyric-generation, voice-synthesis
Timbre transfer is a popular example of Google's Differentiable Digital Signal Processing(DDSP) library. Their autoencoder model is able to make a sung melody sound like it was produced by another instrument such as a violin or a saxophone, but this concept of timbre transfer can't be applied the other way around due to missing lyric information. This project alters the DDSP framework to encode phoneme labels in addition to pitch and loudness to enable the autoencoder to synthesize sung lyrics given a time-aligned melody line.
The goal was to generate interesting approximations of human singing rather than modeling a human singer perfectly; audio where the lyrics could be understood but didn't sound exactly human. The system is made up of 3 stages. First a GRU model generates lyrics, then an LSTM-GAN generates a matching melody line. Finally in stage 3 a DDSP autoencoder synthesizes the voice singing the melody and lyrics. The system in presented in a Google Colab Notebook that allows the user to adjust model parameters and select their favorite outputs from each stage. Try it out yourself, no coding or installations required! You can also read more details about the system design and technical details in the project report I submitted for my graduate Computational Creativity module.
NSynth Super Hardware Build
Lasercut and 3D-printed build of Google Magenta's neural timbre synthesizer
Details Coming Soon
Dynamic Reverb Simulation in AR
Efficiently simulate enviroment specific sound propogation for Microsoft HoloLens
GitHub Link: AR-Reverb
This HoloLens application simulates sound propogation in augmented reality in order to create realistic echo effects that take into acount the topology of the AR environment during reverb calculations. The size and shape of a room, as well as the presence of obstacles, can significantly influence sound, and taking these parameters into consideration can improve imersion in an augmented reality environment. Sound propogation is simulated using a parallelized ray tracing algorithm that approximates how sound bouces around a room by modeling the waves as rays. The result is reverberation effects that can be calculated in real time, and change dynamically each frame as the user moves around the room.
This project was a collaboration with Jonathan Merrin. To approach the problem, we divided the AR space into a custom data structure we called Quadrants, each responsible for keeping track of the spatial mapping data relevant to that section of the room and the rays that intersect it. When the HoloLens grabs more spatial mapping data, we asynchronously request the new information regarding the mesh and send it to the relevant Quadrant. That way, we keep most Quadrants free and ready to do work as they are needed.
When a new sound source is added to the environment, we use Unity's Physics.Raycast to spawn 75 rays originating from the source and calculate where they collide with the walls. On every collision, we spawn a new sound ray reflecting off the object it collided with and dampen the associated volume. We allow this to continue up to a maximum recursion depth of 30 collisions.
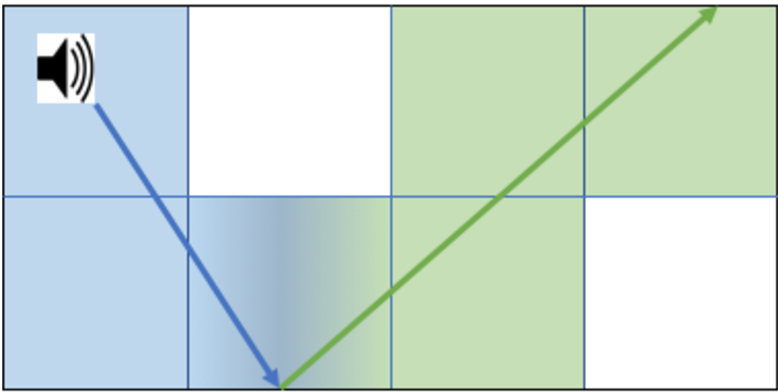
Whenever a ray crosses through a Quadrant, we add it to the Quadrant's list of active rays. On every frame, we check what Quadrant the user's position is in and loop through its active rays to compute which rays come close enough to the user to be heard, eliminating the majority of the rays from the loop. When a sound has completed playing, all of its corresponding rays are destroyed. With our parallelized apparoach, we were able to raytrace a sound in 3ms, less than half the latency of our baseline sequential implementation that took 8ms. For more details on our algorithm and latency measurements, check out the project README on GitHub.
Color Bursts
Generative sound installation in a botanical garden
GitHub Link: color-bursts
Color Bursts is a generative composition created by Sara Adkins and Julian Koreniowsky, inspired by the vibrant flowers scattered throughout a butterfly garden in Pittsburgh. The piece is made up of sample banks of percussive figures and melodic marimba phrases that randomly loop. Short synthesizer bloops flutter above the main loops, playing sparsely on randomly selected sub beat while an evolving drone sounds in the background. Samples for the piece were created using Logic Pro X.


Color Bursts ran as a sound installation in the Phipps Botanical Garden for four months in the summer of 2017. The piece runs as a Pure Data patch, which handles the scheduling and looping of the various voices. The patch runs on a Raspberry Pi, which launches the patch on startup and runs it indefinitely. The Pi was powered by a rechargeable battery that was plugged into a power source, ensuring the system would continue to run even if power was lost for several hours. The Pi was connected to a small but powerful external speaker using a USB audio device. The entire system was compact, and able to be hidden from view in the foliage of the garden.
RobOrchestra
MIDI controllable robotic orchestra with an interface for generative music
GitHub Link: RobOrchestra
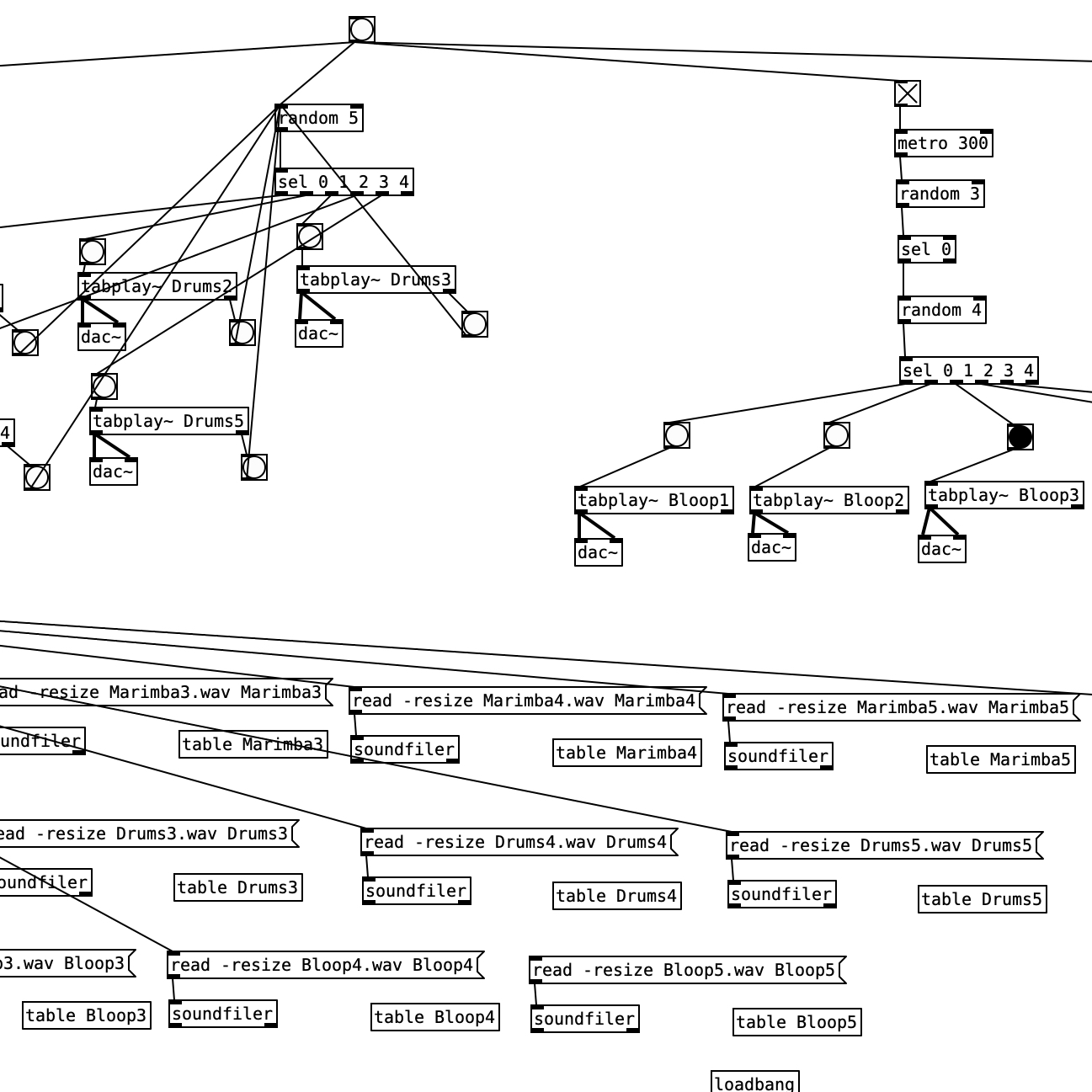
RobOrchestra is an ongoing project in the Carnegie Mellon Robotics Club that aims to explore the creative possibilities for robotic instruments. The RobOrchestra team designs, builds and programs robots that read music from MIDI data in order to put on musical performances. The orchestra, consisting of XyloBot, TomBot, SnareBot and UkuleleBot, has performed at several events across campus including Spring Carnival, Philharmonic Preview Parties, Computer Science Day, and the CMU 50th Anniversary Showcase.


Sara led the RobOrchestra project from 2015-2018, steering the project toward enabling the orchestra to "improvise" unique polyphonic music in real time based off of music generation algorithms, rather than just reading from static MIDI files. The first iteration of this algorithm generated chord progressions using a Markov chain. Xylobot would improvise a melody over the progression, usually sticking to chord tones with some probability of playing passing tones. SnareBot and TomBot would choose a rhythmic feature each measure from a bank. Code for this algorithm was written in Processing, which handled the scheduling of sending MIDI notes to each robot.
Future iterations of generative algorithms introduced a graphical interface, allowing users without any musical background to use the orchestra as a tool to create their own music. Through the GUI, users could control various parameters of the algorithm and test out different keys and modes. Control sliders included tempo, how densely each instrument played, and how often scale tones were played.

In addition to the generative music efforts, the team also focused on developing a new robot instrument named UkuleleBot. This robot was intended to be a rhythm section for the orchestra, strumming chords rather than playing individual notes. Chords are controlled by a fingering plate that sits above the neck of the Ukulele. Each “finger” is a solenoid that presses a pad into the string, and rebounds with a spring when the solenoid is turned off. The solenoids are controlled by an Arduino, which is programmed to interpret note-on MIDI messages into fingerings for 24 different chords.
Configurable MIDI Pedal
Stompbox guitar pedal with configurable MIDI over USB behavior
GitHub Link: midi-pedal
This USB MIDI Stompbox is simple to build, and comes with a Python GUI for configuring the MIDI output of each switch. Its perfect for controlling guitar effects in your favorite DAW, or custom patches in Max/PureData. From the configuration software you can configure each switch to emit Note On, Program Change, or Control Change messages and customize the parameters. You can also set each switch to "Press," "Press and Release," or Cycle mode. In cycle mode, you can loop through different MIDI messages on repeated presses.


The firmware runs on a Teensy4.2 microcontroller, which sends MIDI messages over USB and controls the indicator LEDS. The firmware uses the PacketSerial library to receive COBS encoded messages that live update the pedal's MIDI behavior. Visit the GitHub link above for the circuit schematic, firmware and configuration software.
Can Your Smartphone Touch You Back?
Rendering gradient haptic textures on Android to aid non-visual navigation
IEE Publication: Perceiving texture gradients on an electrostatic friction display
This research project, under the supervision of Dr. Roberta Klatzky, explored the possibilities of incorporating haptic feedback into smartphone and tablet applications. Smartphones and tablets receive touch from users, but most devices don't give tactile feedback. We worked with a device that utilizes haptic technology, the Senseg "Feelscreen" tablet, to investigate its use for virtual textures. The tablet gives the user haptic feedback by varying friction impulses depending on how the user's finger is moving. Our idea was that texture gradients could help people find their direction of movement without having to look at a screen.
We investigated human abilitity to discern texture gradients through a series of user research studies. Subjects swipe across a small area of the tablet to feel a gradient texture. Then they report whether the texture is increasing or decreasing in intensity as they swiped left to right. We developed an Android app to present the textures to the subjects and collect data.
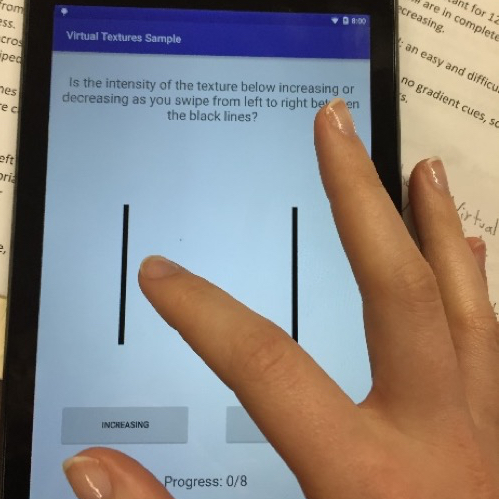
Data was stored and managed using MySQL. We analyzed the data by calculating the discrimination between "increasing" and "decreasing" gradients for each texture. It was found that bumpy textures alongside gradients that started at a low amplitude were easiest to discern. Under these conditions we found discrimination values between 2.5 and 3, supporting the feasibility of using haptics to discern direction of movement.
After seeing positive results, we designed a keyboard application that uses various texture gradients across the keys to enable the user to find their direction of movement and easily "swipe type" on the keyboard without having to look at the screen. Our research was presented at the Meeting of the Minds research symposium in the Spring of 2016 and published in the IEEE World Haptics Conference in 2017.
